.png)

RAG vs Live Search: The Difference That Defines Visibility
RAG vs “Live” AI Search - people keep using these interchangeably.
If you’re a publisher, the difference isn’t academic. It directly impacts whether your content shows up in AI answers… or quietly disappears.
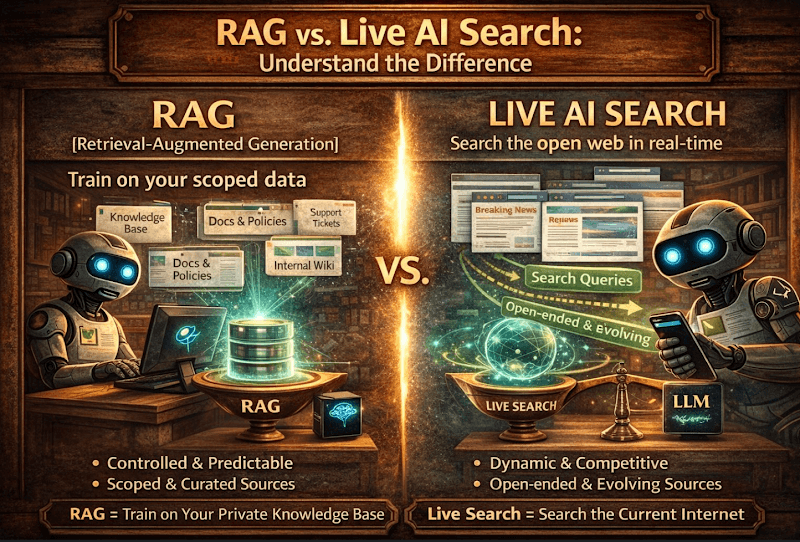
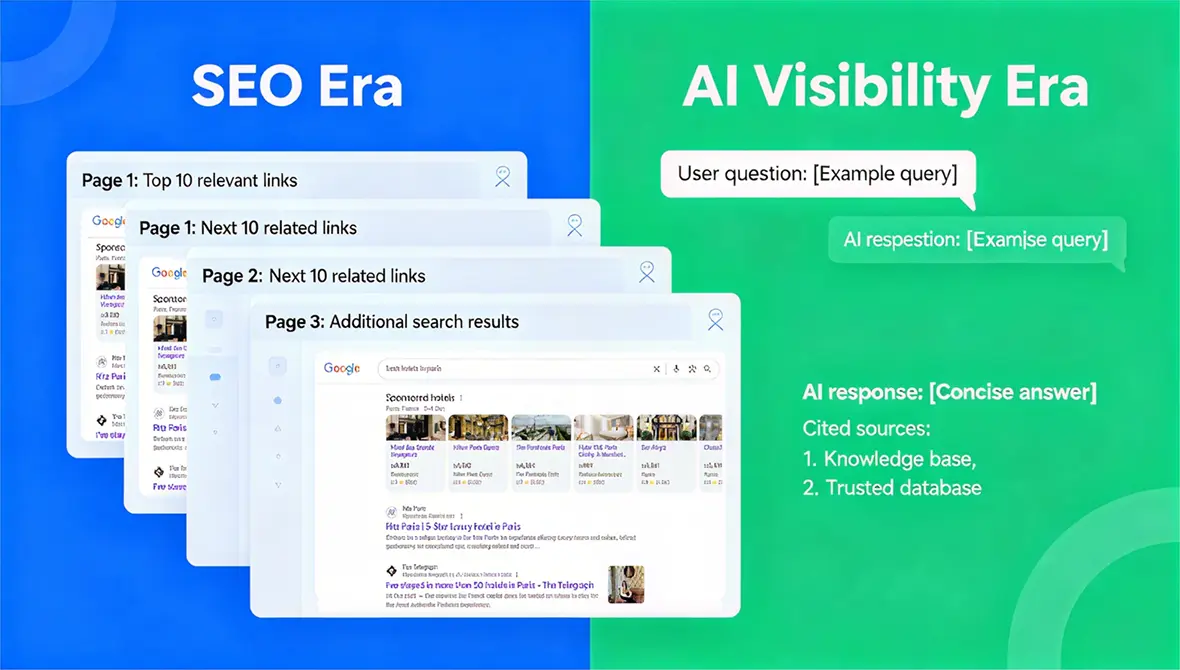
RAG (Retrieval-Augmented Generation) is, at its core, about grounding a model in a predefined set of sources. Before the model answers, it is pointed to a specific corpus - a knowledge base, a curated dataset, or a closed list of trusted sites - and retrieves relevant pieces from there.
It’s controlled, predictable, and bounded. And from a publisher perspective, that has a very clear implication: you either made it into that dataset, or you don’t exist in that system at all.
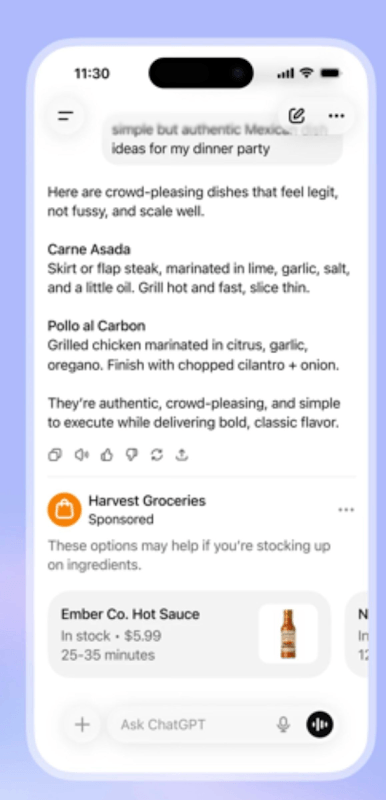
Live AI search works very differently. Instead of relying on a fixed set of sources, the system goes out to the open web in real time. It generates queries, hits search APIs, pulls the top results, visits those pages, and then synthesizes an answer on the fly.
It’s dynamic, competitive, and constantly changing. Which means that every time a query is made, you’re effectively competing again to be one of the sources selected.
So while both are forms of “retrieval,” the underlying mechanics, and the implications, are very different.
With RAG, the problem is inclusion.
With live search, the problem is ranking.
For publishers, this translates directly into how you think about distribution.
In a RAG world, visibility comes from being part of curated datasets, partnerships, or trusted source lists. In a live search world, visibility comes from being ranked high enough to be selected in real time.
If you’re not included in the first, you’re invisible. If you’re not ranked in the second, you’re also invisible.
Which means this isn’t a question of choosing one or the other. You need to think about both layers at the same time: how your content becomes a trusted, included source in closed systems, and how it remains discoverable and competitive in open ones.
Because AI isn’t a single traffic channel. It’s multiple access layers to your content.
And if you’re only optimizing for one of them, you’re missing a big part of how your content will be used going forward.